
Andiamo dritti al punto: con Tensorflow problemi ovunque! In questo log procediamo alla scoperta di @tensorflow/tfjs un pacchetto npm per tensroflowjs.
Ora, con serietà, analizziamo la situazione pragmaticamente.
Scende una lacrimuccia… l’ultimo log è di parecchi mesi fa.
Ricordi?
La prova del MAX Segmenter dell’IBM Stock Exchange è stato l’ultimo progetto di questo tipo.
Come?!
Non sai cosa siano i Log?
Ecco una guida che ne spiega rapidamente la nascita: Cosa sono i log da 0 a 0,001?
Ora, torniamo a noi!
No, tensorflow il framework open source che abbiamo conosciuto qui e con il quale è stato possibile creare velocemente una RNN qualche giorno fa, non è problematico.
La nostra poca conoscenza del framework invece eccome se lo è!
Veniamo al duqnue.
Cosa bolle in pentola?
Il nostro modello, con architettura LSTM, sembra funzionare a dovere: produce melodie testuali in notazione ABC.
Non possiamo ridurci a un semplice progetto su Google Colab, una piattaforma online messa a disposizione da Google per lo sviluppo di progetti di Machine Learning, Deep Learning e molto di più.
Cosa vediamo all’orizzonte?
Il mondo. Dobbiamo rendere il nostro modello disponibile al mondo.
La soluzione?
Il web: un sito, tutti gli utenti del mondo.
In passato abbiamo pacioccato con qualche bel progettino, ma ora dobbiamo inserire la terza e aumentare i giri del motore.
E… Arrivano i problemi.
Tensorflow Problemi: @tensorflow/tfjs
I dubbi sulla piattaforma per lo sviluppo web sono pressoché nulli: useremo React Js, un framework molto popolare per progetti javascript.
Ho scelto React perché lo uso quotidianamente in ambiente lavorativo, e posso quindi concentrarmi sulle altre cose che non conosco.
Tipo Tensorflow.
E’ arrivato il momento di allinearti, spiegando quanto fatto fin’ora.
Nel precedente post, abbiamo portato a termine lo sviluppo di una rete neurale ricorrente (RNN) per la generazione di melodie, e pare funzionare piuttosto bene:
Come rendiamo dunque questa rete neurale accessibile a tutti?
L’idea è quella di convertire il modello con l’ausilio di tensorlfow js, caricarlo nel browser e consentire a chiunque voglia la generazione della propria melodia a partire da un semplice seed.
Il seed è una stringa di lunghezza arbitraria: “x”, “abc”, etc…
Quali sono i quindi i problemi con tensorflow?
Che non funziona una ceppa.
Procediamo con ordine.
A modello ultimato, lo abbiamo esportato con:
# Tensorflow.js import tensorflowjs as tfjs # define the path to which export the model tfjs_target_dir = 'models' tfjs.converters.save_keras_model(model, tfjs_target_dir)
La funzione produce per prima cosa un file model.json che corrisponde a una sorta di ricetta, contenete tutte le indicazioni per la creazione del modello.
In secondo luogo, la stessa funzione genera molteplici file binari il cui contenuto mi è ignoto anche se suppongo siano i weights della rete neurale.
Quindi ricapitolando.
Abbiamo generato il modello, esportato e ora? Lo importiamo nuovamente in browser e il gioco è fatto.
Non proprio.
Non funziona…
Abbiamo importato anche questo modulo ma…
Abbiamo un errore nel caricamento dei wieghts…
E se cambiassimo soluzione?
Intendi tipo tensorflow node?
Si esatto….
TypeError: The “original” argument must be of type FunctionBenissimo. Non è questa la strada corretta.
Abbiamo provato anche a usare l’utility tensorflow coverter per produrre i file necessari a partire da un H5.
Stesso identico problema… quindi pare non sia un problema di conversione, ma di caricamento del modello.
L’articolo è in fase di aggiornamento. Update futuri, saranno riportati qui sotto.
Aggiornamento TensoflowJS 10/04
Siamo riusciti a importare con successo il modello sull’app javascript:
const mod = await tf.loadLayersModel(sourceModel, { strict: false });Ora… il parametro strict è abbstanza violento:
If
strict parametertrue, require that the provided weights exactly match those required by the layers.falsemeans that both extra weights and missing weights will be silently ignored.
Tenuto conto che pare avessimo un problema di missing weights, sono curioso di sapere come si evolverà la faccenda.
Importare il modello è solo una piccola tappa nel nostro lungo viaggio. Infatti provando a fare l’inferenza otteniamo questo errore:
Error: Input 0 is incompatible with layer lstm: expected shape=30,,256, found shape=1,0,256.
Questo perché abbiamo estratto il modello sbagliato.
Velocemente: torniamo al Google Colab ed estraiamo quello corretto, batch_size = 1.
Carichiamo tutto su AWS e prepariamoci ad aggiornare la pagina.
Ottimo. Il modello sembra funzionare, però dobbiamo fixare alcune cose logiche che paiono non essere ottimali.
Mmmmm.
Il modello produce come output sempre la stessa previsione. Poiché usiamo un funzione di sampling per il l’estrazione dell’id dalla previsione potremmo sbaglaire qualcosa a questo punto.
In effetti nella funzione mancava un parametro: temperature, che esprime il grado di casualità con cui estrarre valori dalla distribuzione.
Allora questo è il nostro tensore di previsioni:
Tensor
[[0.2480293, 0.6674649, -0.199247, ..., -0.710799, -0.1965451, 0.3912231],]Otteniamo sempre un id = 82 che non si capisce bene da cosa dipenda.
Come dici?
Controllare la funzione di sampling? Facciamo subito
Tensor
[[NaN, NaN, NaN, ..., NaN, NaN, NaN],]Eh si… abbiamo un problema. La cosa che ora mi chiedo è come sia possibile che da questo Tensore di valori NaN si ottenga 82.
Prima cosa, procediamo a capire da cosa dipendano questi NaN.
Dopo una pausa di 10 ore lavorative, eccoci nuovamente!
Dove eravamo rimasti? Ah si l’82.
RNN Sampling Functions
Dunque. Sono abbastanza convinto che la funzione di sampling non sia ottimale:
const sample = (probs, temperature) => {
return tf.tidy(() => {
const logits = tf.div(tf.log(probs), Math.max(temperature, 1e-6));
const isNormalized = true;
// `logits` is for a multinomial distribution, scaled by the temperature.
// We randomly draw a sample from the distribution.
return tf.multinomial(logits, 1, null, isNormalized).dataSync()[0];
});
}Il curioso parametro temperature è una misura della casualità. Facenfd alcune ricerche in rete ho trovato un’altra funzione di sampling, simile:
const argMax = (array) => {
return Array.from(array).map((x, i) => [x, i]).reduce((r, a) => (a[0] > r[0] ? a : r))[1];
}
const sample = (preds, temperature=1.0) => {
const predsTemperature = preds.map((prob) => Math.exp(Math.log(prob) / temperature) )
const mult = SJS.Multinomial(1, predsTemperature);
return this.argMax(mult.draw());
}
Questa funzione, che ho trovato qui, fa uso della seguente libreria:
Un modulo che supporta diverse distribuzioni:
- Bernoulli
- Binomial
- Discrete
- Multinomial
- Poisson
- Negative Binomial
Nessuna di queste è la categorical distribution che stiamo usando sul progetto colab.
L’alternativa comunque c’è: si chiama categorical-distribution ed è anch’esso un modulo NPM.
Solo che non intendo perdere troppo tempo a capire come configurarla, e per questo preferirei optare per qualcosa di già pronto.
Implementiamo il codice di cui sopra.
Si. Magari tu lo hai capito in pochi secondi, a me sono ci sono volute parecchie decine di minuti per comprendere che quei due codici, seppur con sistemi differenti, calcolano la stessa cosa. Grandissimi.
Hai provato a cercare meglio?
Dici su internet?
Sì. Guarda questo link.
Fantastico, quel tipo ha il nostro stesso problema! Leggiamo un po’.
Ottimo appena 2 giorni fa: non siamo soli.
Ho prontamente seguito il ragazzo, per’altro ingegnere di Uber, su Twitter e Linkein.
Comunque, c’è anche questa fonte che sostanzialmente è la funzione in python di cui abbiamo bisogno e che potremmo quindi implementare.
Ma.. sai com’è… prima di creare da zero tutto… specie perché non ho tutte queste competenze… e non intendo investire così tanto tempo…
Cerchiamo ancora.
UUUH
Mentre facevo delle ricerche ho trovato questo, un engine open source per la conversione da ABC notation. Potrebbe tornarci utile in futuro.
Tensorflow Problemi: Aggiornamento 11/04
Alle ore 8:32 di sabato 11 aprile 2020 inizia una nuova fase di lavoro.
Siamo tutti allieanati, procediamo.
Focalizziamo l’obiettivo.
Ieri abbiamo concluso sostenendo che il problema fosse attorno alla funzione di sampling.
Per sicurezza, accertando quindi che il difetto sia localizzato in quel punto, andiamo a vedere come risulti costituito il nostro modello:
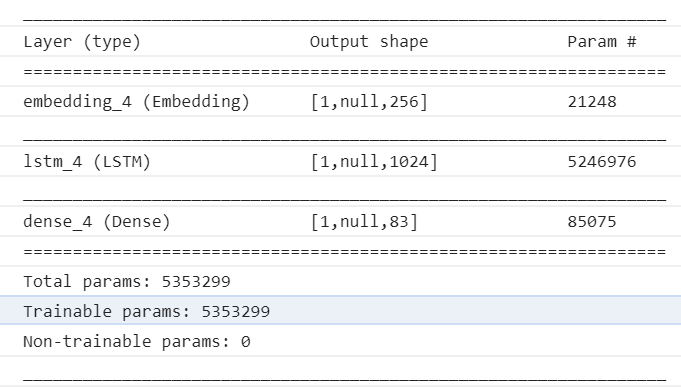
E’ una cosa che avremmo dovuto controllare prima, anche se sarebbe stato superfluo. Il summary ci informa che il modello è stato importato correttamente.
Cosa sbagliamo?
Un caldo abbraccio, Andrea.



