
In questo semplice Tensorflow tutorial italiano vedremo come realizzare una CNN in Tensorflow per un task di machine learning classification sul MNIST Dataset: ecco il Tensorflow MNIST Tutorial in Italiano.
Ora potresti chiederti per quale motivo questa introduzione sia così ricca e densa di parole, poco fluida e con un leggero attrito nella lettura.
Indicizzazione SEO.
Un’annosa questione fondamentale per portare traffico organico nel sito.
Ti ho svelato questo particolare perché intendo essere assolutamente onesto e trasparente con te: due parole chiave in questo blog!
Senza ulteriori indugi, iniziamo.
Tensorflow MNIST Tutorial: Machine Learning Hello World
Nella nostra introduzione a Tensorflow, punto d’inizio nel nostro viaggio alla scoperta di Tensorflow, abbiamo compreso cosa siano i Tensor, e come funzioni questo versatile framework open source.
Oggi passiamo dalla teoria alla pratica, operando un task di machine learning classification in Tensorflow con il MNIST dataset.
Il MNIST (modified National Institute of Standards and Technology datatabase) è una collezione di 70,000 immagini di 10 cifre scritte a mano, di ridotta dimensione (28×28 pixel), in bianco e nero e con dunque un solo canale colore.
Le caratteristiche di questo dataset lo rendono perfetto per un Tensorflow Tutorial, ottimo dunque per muovere i primi passi con un semplice machine learning classification problem.
La regola non scritta della programmazione invita a stampare due parole, Hello World, ogni qualvolta si impari un nuovo linguaggio: un primo semplicissimo task che permette di prendere dimestichezza con la sua sintassi.
Sappiamo entrambi che il machine learning è tutto fuorché un linguaggio di programmazione e possiamo considerare l’Hello World come un altrettanto semplice task per apprendere importanti nozioni.
Non finisce qui.
Per completezza d’informazione, ti informo che esiste una versione modificata del MNIST, chiamata Fashion MNIST (GitHub), contenente sempre 70.000 immagini in bianco e nero, di 10 prodotti differenti, provenienti dal sito di Zalando.
Sottoporrà le nostre reti neurali a uno stress superiore e lo useremo nei prossimi laboratori.
In questo Tensorflow MNIST Tutorial rimarremo fedeli al dataset originale per creare un tesnorflow classificator: prima useremo una semplice Rete Neurale (NN), poi una Rete Neurale Convoluzionale (CNN)
Iniziamo subito con l’importare le librerie e iniziare l’esplorazione del dataset!
MNIST Dataset | Data Exploration
Puoi eseguire l’intero Tensorflow MNIST Tutorial sul tuo personale Google Colab.
Ti ho presentato questo efficace strumento, che mette a disposizione una GPU gratuita solo per te, in questo post!
In fondo al post troverai comunque il link che ti presenta il progetto completo.
Apriamo Google Colab e iniziamo subito a importare le librerie necessarie.
# libraries needed
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import random
from tqdm import tqdmOpzionalmente possiamo verificare di aver scelto la runtime corretta tra CPU, GPU e TPU (Tensor Processing Unit, unità hardware progettata per eseguire con efficienza i tensor di Tensorflow) usando questo codice:
# Check that we are using a GPU, if not switch runtimes
# using Runtime > Change Runtime Type > GPU
assert len(tf.config.list_physical_devices('GPU')) > 0Procediamo quindi con l’estrazione del dataset.
Prima di procedere c’è una cosa che devi sapere.
Il MNIST Dataset è organizzato in due set d’immagini e labels; il primo, di 60.000 campioni, pensato per il training, mentre il secondo di 10.000 è usato per il test del modello.
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()Inizia la fase di Data Exploration, che ti ricordo essere quell’importante attività in cui facciamo la conoscenza del set di dati comprendendone le peculiarità.
Visualizziamo le dimensioni del MNIST Dataset:
print(f"Train Images:{train_images.shape}")
print(f"Train Labels:{len(train_labels)}")
# Train Images:(60000, 28, 28)
# Train Labels:60000
Come anticipato, il Training Set è composto da 60k immagini da 28×28 pixel.
Prendiamoci ora del tempo per analizzare alcuni campioni selezionati casualmente dal gruppo.
Lo facciamo creando una griglia quadrata di 36 elementi attraverso matplolib e con l’ausilio di un semplice ciclo.
Nota una cosa.
np.random.choice, genera una serie casuale da un 1-D array, o numero intero.
La logica è generalmente quella dell’inclusione del valore minore e di esclusione di quello maggiore, motivo per cui passando 60000 faremo scegliere casualmente alcuni numeri da 0 a 59999.
In questo caso i numeri scelti, specificati dal secondo parametro, saranno 36.
Ecco il codice:
# set a proper figure dimension
plt.figure(figsize=(10,10))
# pick 36 random digits in range 0-59999
# inner bound is inclusive, outer bound exclusive
random_inds = np.random.choice(60000,36)
for i in range(36):
plt.subplot(6,6,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
image_ind = random_inds[i]
# show images using a binary color map (i.e. Black and White only)
plt.imshow(train_images[image_ind], cmap=plt.cm.binary)
# set the image label
plt.xlabel(train_labels[image_ind])
Ora esaminiamo con più attenzione una singola immagine.
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()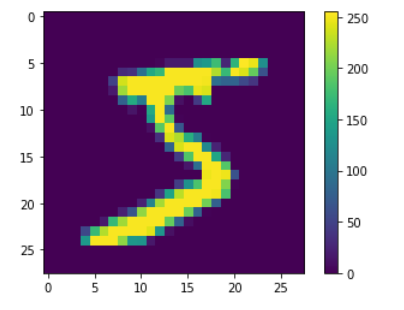
Questo grafico merita un attimo di attenzione.
È chiaro che sappiamo molte cose sul dataset perché il MNIST è popolare e ben documentato. Il mondo reale è ben diverso.
Immagina di lavorare per un’azienda che si trova a gestire un dataset nuovo che il cliente ha fornito senza alcuna informazione aggiuntiva: in questo caso saper estrarre informazioni utili è fondamentale.
Impariamo allora a piccoli passi, descrivendo il grafico superiore.
Stiamo esaminando un’immagine quadrata di 28 pixel per lato (lo vediamo dagli assi), con una color map che ci fa capire nettamente come le sfumature di grigio definiscano i contorni della cifra.
Ogni pixel ha poi un valore compreso tra 0 e 255. Questo è importante, perché devi sapere che i valori devono essere normalizzati per essere processati da una rete neurale.
Scaliamoli.
# from range 0-255 to 0-1
train_images = (np.expand_dims(train_images, axis=-1)/255.).astype(np.float32)
train_labels = (train_labels).astype(np.int64)
test_images = (np.expand_dims(test_images, axis=-1)/255.).astype(np.float32)
test_labels = (test_labels).astype(np.int64)Tensorflow Tutorial Neural Network | Costruzione della rete
Normalmente passeremmo molto più tempo ad analizzare ed elaborare i dati, pulendoli opportunamente e trasformandoli all’occorrenza.
Trattandosi di un task semplice, in questo Tensorflow MNIST Tuorial salteremo queste fasi per concentrarci fin da subito sulla costruzione della rete.
Consoci la teoria dietro il training di una rete neurale vero?
Ottimo mi capirai senza problemi allora.
La nostra rete avrà due fully connected layes per risolvere il classification task e produrre come ouput una distribuzione di probabilità sulle 10 classi (i.e. le cifre tra 0 e 9).
L’architettura è espressa qui:
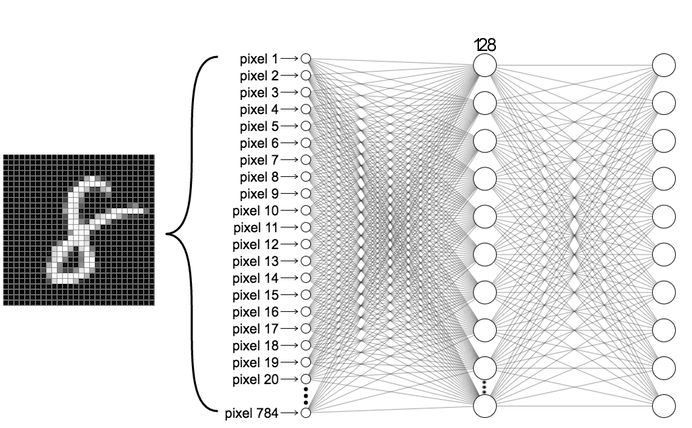
Il processo si basa sulla conversione dell’immagine di 28×28 pixel in un vettore, chiamato feature vector di 784 pixels.
È come se facessimo esplodere l’immagine e allineassimo i singoli pixel in una sola riga.
Useremo le API di Keras per definire l’architettura della rete. Nello specifico impiegheremo l’API Sequential e useremo un Flatten e due Dense Layer, l’ultimo con 10 neuroni, uno per ogni classe, e una softmax come funzione di attivazione, necessaria per la distribuzione di probabilità.
La funzione softmax converte, passami il termine, i numeri in input in una sequenza pesata di valori con somma 1.
Per darti un’idea, con un input di (1,2,3,4,1,2,3), la softmax produce: (0.024,0.064,0.175,0.475,0.024,0.064,0.175).
Lo so che hai rifiutato di leggere i numeri.
Sappi allora che il valore 4 ha un peso in uscita 20 volte superiore a quello del valore 1. Niente male.
Sento le tue dita fredde. Riscaldiamole con un po’ di codice:
def build_fc_model():
fc_model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dense(10,activation="softmax"),
])
return fc_model
model = build_fc_model()Capiamo un attimo quello che abbiamo fatto.
Il primo livello della rete, il Flatten, appiattisce l’immagine passando da due dimensioni, un array bidimensionale o 2D-array di 28×28, a una dimensione, un array monodimensionale o 1D-array di 784 pixels.
Non ci sono parametri di apprendimento in questo livello: avviene sono una semplice trasformazione.
La sequenza di due fully connected Dense layers è diversa.
Il primo livello, il secondo della rete, ha 128 neuroni o nodi.
Il secondo livello, il terzo della rete, ha 10 neuroni o nodi, ciascuno dei quali contiene un valore che esprime la probabilità che l’immagine in ingresso appartenga a quella classe.
Tensorflow Tutorial Neural Network | Compilare il modello
Prima di allenare il modello, dobbiamo definire alcune impostazioni che sono aggiunte al modello durante la compilazione.
Ci sono tre elementi importanti:
- Loss Function – Definisce il criterio con cui valutare l’accuratezza del modello durante l’allenamento. L’obiettivo è minimizzare la funzione
- Optimizer – Definisce il criterio di aggiornamento del modello sulla base dei dati osservati e della Loss Function
- Metrics – Risponde alla domanda “oh ma sto ***** modello funziona?”, monitorando il training e il testing del modello. In questo Tensorflow MNIST Tutorial useremo l’accuracy.
Per il momento possiamo iniziare con uno Stochastic Gradinet Descent (SGD) come ottimizzatore applicando un learning rate di 0.1.
Infine opteremo per un cross entropy loss come Loss Function, poiché stiamo risolvendo un task di classificazione categorica.
Stiamo mettendo molta carne al fuoco, ma per gustarci la grigliata possiamo anche non sapere come si cucina.
Poiché è quasi orario di cena è ho l’acquolina in bocca, uso ancora la metafora.
Ti insegnerò a marinarla e capire la cottura adeguata a ogni taglio di carne, ma per il momento rimaniamo sul superficiale.
learning_rate=1e-1
optimizer = tf.keras.optimizers.SGD(learning_rate)
loss='sparse_categorical_crossentropy'
metrics=['accuracy']
model.compile(
optimizer,
loss,
metrics,
)Con il nostro modello compilato, possiamo procedere all’allenamento.
Tensorflow Tutorial Neural Network | Allenare il modello
Allenare il modello significa fornirgli i dati di allenamento (i.e. Training data) e chiederli d’imparare le associazioni tra immagini e label.
Carino.
Dobbiamo prima definire due costanti:
- bacth_size, il numero di campioni analizzati prima aggiornare i parametri del modello
- epochs, il numero di passaggi completi su tutto il training dataset. In un’epoca, tutti i campioni sono stati presi in considerazione dal modello.
Il valore di questi parametri è scelto in una serie di tentativi, ed esiste un processo preciso per tararli correttamente.
Noi… beh… Prenderemo due parametri, non proprio casuali… Diciamo che funzionano.
batch_size = 64
epochs = 10
model.fit(
train_images,
train_labels,
batch_size,
epochs,
)Ognuna delle 10 epochs avrà 938 batches da 64 samples ciascuno.
Presta attenzione al valore di accuracy nel log del modello: dovrebbe essere qualcosa di vicino a 0.99
Ora testiamo il modello su dati che non ha mai visto: il testing set.
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"Test accuracy: {test_acc}")
# 313/313 [==============================] - 1s 2ms/step - loss: 0.0733 - accuracy: 0.9778
# Test accuracy: 0.9778000116348267Una volta allenato e testato con il codice superiore ecco che raggiungiamo un’accuratezza di 97.8% sul testing set.
Sai cosa significa avere un’accuratezza in allenamento superiore a quella di test?
Esatto overfitting, quando un modello di machine learning performa peggio sui dati nuovi che su quelli di allenamento.
Mmm posiamo fare di più.
Vediamo ora come creare una CNN per risolvere lo stesso problema.
Tensorflow MNIST Tutorial | Tensorflow CNN – Convolutional Neural Network
Le reti neurali convoluzionali (Convolutional Neural Network, CNN) sono particolarmente utili per una varietà di task nella computer vision, e hanno raggiunto prestazioni pressoché perfette sul MNIST.
Motivo per cui è stato sviluppato il Feshion MNIST, ma lo vedremo in un prossimo laboratorio.
Ti metto qui il link per la teoria delle Convolutional Neural Networks, così se più avanti dovessi trovare qualche termine sconosciuto puoi fare affidamento al blogpost conciso e completo.
Per questo task di classificazione, ci affideremo a un’architettura semplice ma efficace. Eccola:
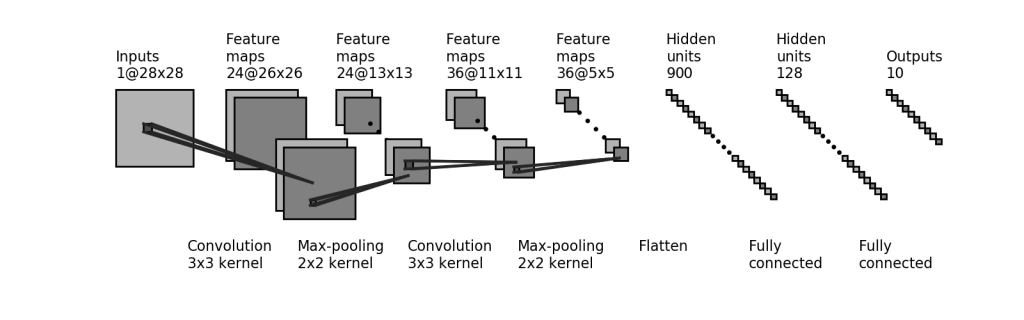
Non temere, tra pochissimo descriveremo ogni sua parte.
Devi sapere che nella nostra Convolutional Neural Network possiamo distinguere due parti fondamentali.
La prima, definita di Feature Learning, comprende una serie di filtri che, applicati all’immagine in ingresso, consentono di estrarre importanti informazioni (e.g. sagome, linee, bordi, etc…).
La seconda, definita di Classification, prende l’immagine elaborata, ridotta e convertita in un vettore, il feature vector, e attraverso una rete neurale ne calcola la classe di appartenenza, in modo analogo a quanto visto in precedenza.
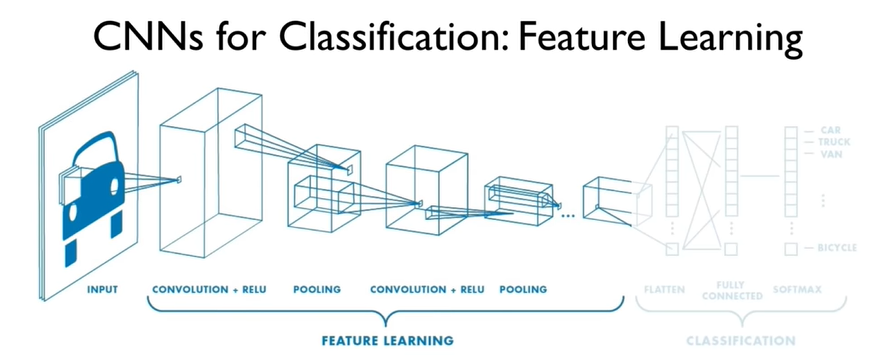
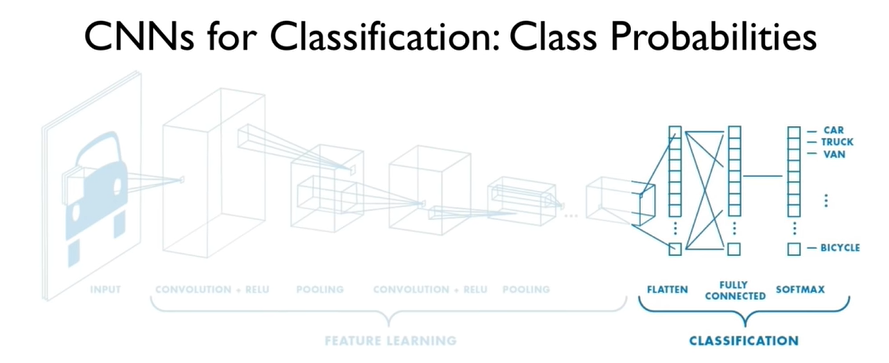
Per definire l’architettura della Convolutional Neural Network in Tensorflow useremo l’API di Keras ancora una volta. Avremo però bisogno di due nuovi livelli:
- Conv2D, i layer convoluzionali per estrarre le informazioni
- MaxPool2D, i layer di pooling per ridurre lo spazio vettoriale (i.e. il feature space) e diminuire la complessità computazionale
Procediamo:
from tensorflow.keras import layers, models
def build_cnn_model_improved():
cnn_model = models.Sequential()
# Feature Learning block:
cnn_model.add(layers.Conv2D(24, (3,3), activation='relu', input_shape=(28,28,1)))
cnn_model.add(layers.MaxPooling2D((2,2)))
cnn_model.add(layers.Conv2D(36, (3,3), activation='relu'))
cnn_model.add(layers.MaxPooling2D((2,2)))
# Classification block:
cnn_model.add(layers.Flatten())
cnn_model.add(layers.Dense(128, activation='relu'))
cnn_model.add(layers.Dense(10, activation='softmax'))
return cnn_modelNel Google Colab, in fondo al blogpost, troverai anche una versione verbosa, dell’architettura.
Potresti provare smarrimento, ma si tratta della stessa funzionalità solo più prolissa.
Tornando a noi verifichiamo le specifiche:
cnn_model = build_cnn_model_improved()
# Print the summary of the model
print(cnn_model.summary())Model: "sequential_14" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_34 (Conv2D) (None, 26, 26, 24) 240 _________________________________________________________________ max_pooling2d_30 (MaxPooling (None, 13, 13, 24) 0 _________________________________________________________________ conv2d_35 (Conv2D) (None, 11, 11, 36) 7812 _________________________________________________________________ max_pooling2d_31 (MaxPooling (None, 5, 5, 36) 0 _________________________________________________________________ flatten_15 (Flatten) (None, 900) 0 _________________________________________________________________ dense_29 (Dense) (None, 128) 115328 _________________________________________________________________ dense_30 (Dense) (None, 10) 1290 ================================================================= Total params: 124,670 Trainable params: 124,670 Non-trainable params: 0 _________________________________________________________________ None
Tensorflow CNN – Convolutional Neural Network Training
Come prima, procediamo all’allenamento della rete impostando un ottimizzatore, una funzione di costo, e una metrica per definire le prestazioni del modello.
Aggiungiamo il batch_size e il numero di epoche e via!
cnn_model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
batch_size = 64
epochs = 10
train_job = cnn_model.fit(
train_images,
train_labels,
batch_size,
epochs,
)Possiamo ora testarne le prestazioni:
test_loss, test_acc = cnn_model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
# 313/313 [==============================] - 1s 3ms/step - loss: 0.0403 - accuracy: 0.9918
# Test accuracy: 0.9918000102043152Ottimo! 99.18% di accuratezza, ci siamo!
Per inciso, nella vita reale i valori assoluti raramente sono significativi.
A volte un classificatore che abbia il 60% di accuratezza è considerato ottimo, se migliora un errore umano con un 30% di accuratezza.
Significa prestazioni incrementate del 100%!
Tornando a noi, facciamo qualche previsione.
Predictions
predictions = cnn_model.predict(test_images)
predictions[0]
'''
array([7.5341636e-14, 9.4733418e-15, 3.5006824e-12, 2.6328737e-09,
1.3520282e-10, 1.6230203e-12, 4.6676954e-21, 1.0000000e+00,
2.8423539e-14, 4.9699383e-10], dtype=float32)
'''Come vedi, la previsione restituisce un array di 10 valori, una probabilità per ogni classe che sommate corrispondono a 1.
Volendo essere pignoli, una classe è proprio 100%. Approssimare costa.
Questa visualizzazione è pessima. Miglioriamola!
Definiamo un array di class_names, e due funzioni che per il momento non spieghiamo nel dettaglio.
# Define classnames for improved readability
class_names = ['Zero', 'One', 'Two', 'Three', 'Four',
'Five', 'Six', 'Seven', 'Eight', 'Nine']
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')Ora con un altro piccolo snippet di codice stampiamo una griglia di alcuni sample con le rispettive previsioni:
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, np.squeeze(test_images))
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()
Siamo dunque giunti alla conclusione del nostro Tensorflow MNIST Tutorial Italiano per la creazione di una Convolutional Neural Network.
Prossimamente, rimanendo in linea con il lavoro sulla Privacy Preserving AI applicheremo dei concetti di tutela della privacy ai dati, riprendendo quanto fatto in questo laboratorio.
A questo link trovi il Google Colab completo con tutti i codici eseguibili per una guida ancora più dettagliata, ovviamente in inglese.
Per il momento è tutto.
Per aspera, ad astra.
Un caldo abbraccio, Andrea.



