
Tensorflow 2 è un framework open source per il machine learning che agevola lo sviluppo di reti neurali, e supporta potenti librerie come ad esempio Keras e PyTorch.
Abbiamo definito cosa sia il machine learning, fornendo alcuni esempi concreti. Quello che non abbiamo fatto è stato sporcarci le mani con del codice e iniziare a costruire e sperimentare le reti neurali.
In questo post risolveremo un problema usando il machine learning, attraverso la creazione di una piccola, piccolissima, rete neurale.
Preparati per addentrarti nel magico mondo del deep learning , grazie a Tensorflow 2 .
Deep Learning con Tensorflow 2
Il Deep Learning (Apprendimento Profondo), come il machine learning, è definito in molti modi, poiché molteplici sono i punti di vista da cui la definizione nasce.
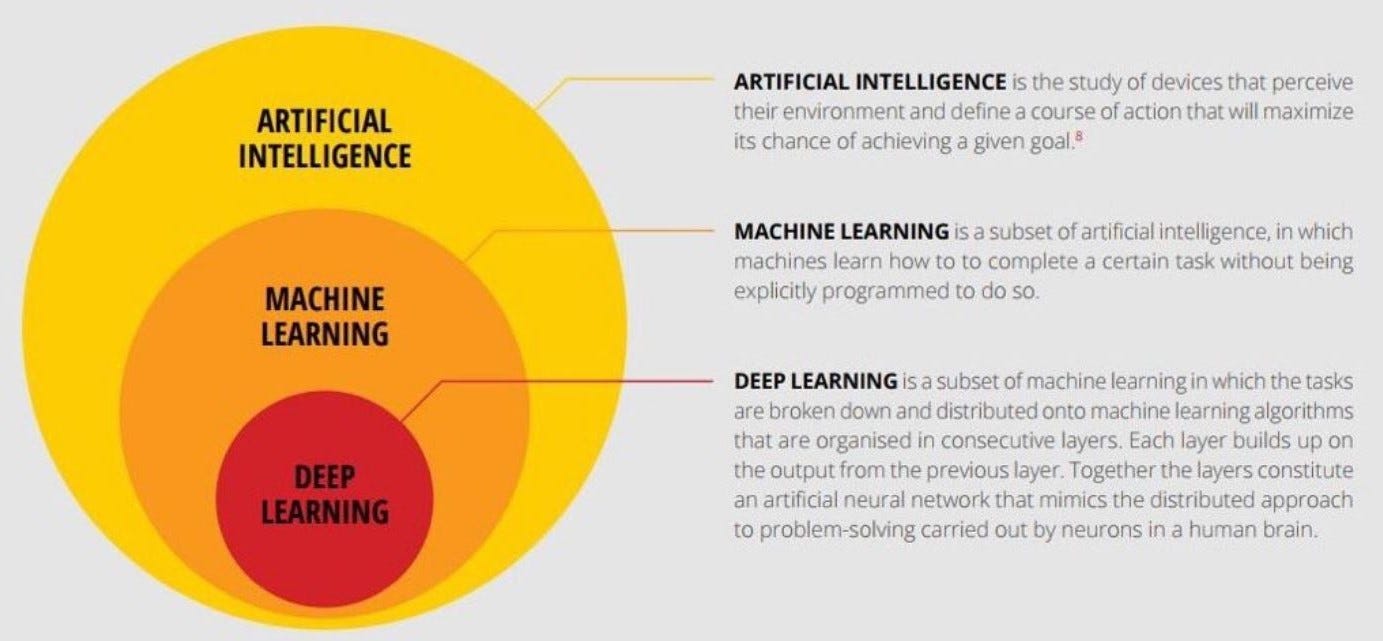
È un metodo, una branca di studi, una classe di problemi… spesso lo si rappresenta come un sottogruppo del machine learning, a sua volta racchiuso in modo più vasto dall’insieme delle Intelligenze Artificiali.
Al di là della definizione, la nostra mente da ingegnere prende il sopravvento.

Quello che realmente ci interessa è capire come usare in modo pratico il deep learning, quali tipologie di problemi è in grado di risolvere, e come possiamo generare business value da essi. A mio avviso, l’aspetto più interessante.
Perché un Toy Problem
Sappiamo che per risolvere un qualsiasi problema sia necessario determinare un metodo. Quando la complessità aumenta, il divide et imperia è tra i più efficaci.
Come ci spiega Nada, questo metodo si sta rivelando fondamentale per lo sviluppo delle auto a guida autonoma.
È una metodologia che suggerisce la scomposizione del problema in sotto problemi, ciascuno dei quali può quindi essere analizzato e risolto in modo abbastanza selettivo e compartimentale. Dall’unione delle soluzioni, si delinea la Big Picture: abbiamo conquistato il nostro ambito traguardo.
Ora concentriamoci sui sotto problemi.
Quello che possiamo fare è realizzare delle situazioni ipotetiche, degli ambienti che riproducano il quesito, semplificandolo, da nuovi punti di vista.
Dobbiamo giocare.
Dobbiamo creare un problema giocattolo, un Toy Problem.
Perché un toy problem? Perché attraverso un esempio pratico comprendiamo un concetto anche complicato.
Tensorflow 2 toy problem: convert °C to °F

So cosa stai pensando.
Il convertitore Celsius-Fahrenheith è un noioso programmino del primo anno di Università.
Nessuno ha mai detto che i Toy Problem fossero divertenti, però hey… Useremo il deep learning, non sei entusiasta?

Amico… fatti… fatti una tazza di camomilla… mi fai paura… sembri un sasso…
Prima di giudicare, ecco cosa imparerai risolvendo un problema banale come questo:
- Conoscenza intuitiva del funzionamento del machine learning
- Esempio pratico da condividere con gli amici di deep learning
- Elementi costitutivi di una rete neurale
- Importanti metriche da tenere presente quando sviluppi una rete neurale.
Non proprio il classico convertitore in C del primo anno d’informatica insomma.
Ci siamo dilungati parecchio, e non abbiamo scritto ancora alcun codice. Non ci piace!
Cosa ne dici? Iniziamo!
Seguendo questa breve guida, accedi a Google Colab e apri un limpido Jupyter Notebook.
Iniziamo coi convenevoli: scriviamo del codice di dubbia utilità, la cui comprensione richiederebbe un post separato. Ora il nostro interesse sono le reti neurali, il resto sarà approfondito successivamente.
from __future__ import absolute_import, division, print_function, unicode_literals try: # Use the %tensorflow_version magic if in colab %tensorflow_version 2.x except Excpetion: pass import tensorflow as tf
Ora importiamo i pacchetti tradizionali e settiamo il log dei soli errori:
import numpy as np import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
Qual è la differenza rispetto a un approccio tradizionale? Beh al primo anno di università andremmo a inserire con molta nnonchalance la formula di conversione… che al momento non ricordiamo diamine!
Non c’è problema. Non temere.
Certo Lord Kelvin si è rivoltato nella tomba a sentici dire che non ricordiamo la formula di passaggio da Celsius a Fahrenheit, ma i tempi sono cambiati.
Oggi non ci serve!
Tutto quello di cui abbiamo bisogno è una manciata di temperature in entrambe le unità di misura:
celsius = np.array([0,-20,-10,15,34,120,-273.15]) fahrenheit = np.array([32,-4,14,59,93.2,248,-459.67])
Abbiamo creato due Numpy Array, in pratica array con qualche funzionalità in più che per il momento non ci serve sapere.
Fantastico.
Ora per acquisire il rispetto di Lord Kelvin, andiamo a creare una rete neurale.
Per questo banale problema, iniziamo con il definire un solo layer, cioè un livello di apprendimento.
Ok propriamente non possiamo definirlo deep learning: è un superficial learning.

model = tf.keras.Sequential([ tf.keras.layers.Dense(units=1,input_shape=[1]) ]) #the below code is the same l0 = tf.keras.layers.Dense(units=1,input_shape=[1]) model = tf.keras.Sequential([l0])
Innanzitutto puoi vedere che stiamo usando Keras, un framework per lo sviluppo rapido di reti neurale, e che abbiamo incontrato anche in passato per risolvere un problema pressoché identico.
Davvero se ci clicchi sopra, non cambia quasi nulla. Ma hey… questo è tensorflow 2! (Non cambia nulla ssshhh)
Alcune informazioni utili alla comprensione:
- input_shape=[1] indica che l’input è un array monodimensionale
- units=1, indica invece il numero di neuroni all’interno della rete neurale, in altri termini corrisponde al numero di variabili interne di cui la rete si avvale per risolvere il problema.
In una rete neurale output di un layer deve corripndere all’input_shape di quello successivo. Tra poco lo vedremo.
Definito il modello, eseguiamone il training con 2000 epoche, o iterazioni, e vediamo il risultato.
model.compile(loss='mean_squared_error',
optimizer=tf.keras.optimizers.Adam(0.1))
history = model.fit(celsius, fahrenheit, epochs=2000, verbose=False)
print("Finished training the model")Abbiamo usato il mean_squared_error come loss function e Adam come ottimizzatore.
Il verbose è un argomento che banalmente indica la tipologia di visualizzazione del progresso di training, come spiegato egregiamente in questo post su stackoverflow.
Perfetto, a training finito diamo un’occhiata al grafico della perdita usando matpotlib, preziosa libreria di creazione grafici.
import matplotlib.pyplot as plt
plt.xlabel('Epoch Number')
plt.ylabel("Loss Magnitude")
plt.plot(history.history['loss'])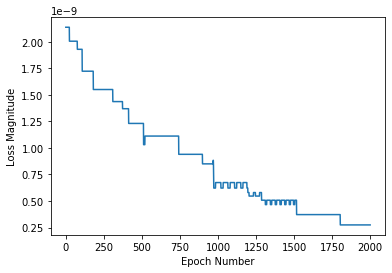
print(model.predict([100.0]))
Ed ecco il nostro risultato…. [[212.]]
Perfetto!
Una rapida esplorazione delle variabili del layer dimostra che effettivamente il training ha avuto successo:
#l0 is undefined if you choose to create the layer inside model initialization
print("These are the layer variables: {}".format(l0.get_weights()))Puoi reperire il progetto originale qui.
Giusto un’ultima considerazione prima di lasciarti.
Complicare un modello non produce necessariamente un aumento delle prestazioni, anzi.
Un esempio? Passiamo da una configurazione a singolo layer, a una con tre. Tutti Dense.
l0 = tf.keras.layers.Dense(units=4, input_shape=[1]) l1 = tf.keras.layers.Dense(units=4) l2 = tf.keras.layers.Dense(units=1)
Un Dense layer, dal punto di vista matematico, è una moltiplicazione tra matrice e vettore.
Un caldo abbraccio, Andrea.



