
Quando le classi della variabile target sono più di due, un classificatore binario (binary classifier) non basta: entrano in gioco i multiclass classifiers (o multinomial classifiers).
Un binary classifier distingue due classi, che per convenzione definiamo positiva e negativa. Evidentemente un multiclass classifiers distinguerà più di due classi.
Multiclass Classifiers
Devi però sapere che mentre alcuni algoritmi sono capaci di gestire classi multiple senza particolari accorgimenti, altri sono rigorosamente dei binary classifiers.
Più nello specifico, tra gli algoritmi maggiormente noti:
- Random Forest & naive Bayes => multiclass classifiers
- Supported Vector Machines (SVM) & Linear classifiers => striclty binary classifiers
Esistono comunque differenti strategie con cui possiamo usare un classificatore binario per previsioni multiclasse. Vediamone due.
One Versus All (OvA)
Il metodo One Versus All, abbreviato in OvA e spesso chiamato One Versus The Rest (one-versus-the-rest), prevede l’impiego di tanti classificatori binari quanti sono le classi da prevedere, ciascuno allenato a riconoscere una specifica classe.
Preso il popolare dataset MNIST (contenete hand-written numbers da 0 a 9), servirebbero 10 classificatori, poiché 10 sono le effettive classi presenti.
Al momento della classificazione di una nuova immagine, ciascun classificatore calcolerà un punteggio e spetterà a noi selezionare la classe con quello più alto.
One Versus One (OvO)
Il metodo One Versus One (one-versus-one), abbreviato in OvO, allena un classificatore binario per ciascuna coppia di classi.
Calcolo combinatorio alla mano, ecco la formula per capire di quanti binary classifiers abbiano bisogno. Con N pari al numero di classi:
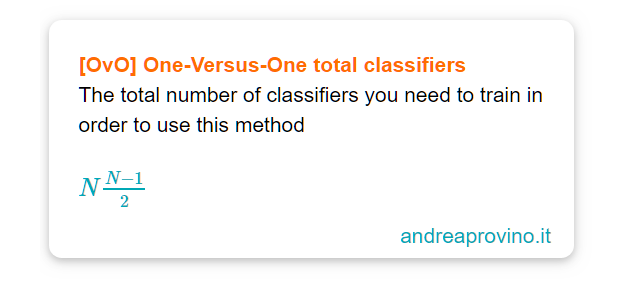
Sul MNIST? Sono 45 binary classifiers…
Perché quindi usare un sistema simile?
Il principale vantaggio del metodo One Versus One (OvO) è che ogni classificatore ha bisogno di essere allenato solamente in un sottoinsieme del dataset contenente unicamente le classi da distinguere.
OvO vs OvA
Quale scegliere?
Le prestazioni di alcuni algoritmi, tra cui il Support Vector Machine, degradano rapidamente con l’aumentare dei dati, specie per i tempi di training richiesti.
Pertanto è preferibile allenare molteplici classificatori su sezioni contenute di dati, anziché agire nel modo opposto. Scelta migliore? In questo caso OvO.
Non è così semplice. Spesso si preferisce impiegare l’OvA sulla maggior parte dei classificatori binari.
Ancora una volta, la risposta è dipende!
Scikit–Learn tuttavia risolve questo problema per noi. Analizzando le caratteristiche dell’algoritmo scelto, in relazione ai dati presenti, automaticamente esegue l’OvA se tentiamo l’uso di un binary classifiers per un problema mutliclasse.
Solo se usiamo un Supported Vector Machine classifiers, viene usato necessariamente l’OvO.
Un caldo abbraccio, Andrea.



