
In questo esploriamo tre Data Visualization Tools in Python: Area Plots, Histograms e Bar Charts.
Data Visualization
Per Data Visualization si intende quella tecnica che consente di esplorare e rappresentare i dati sotto forma di grafici e rapporti, con l’intento di svilupparne una conoscenza globale.
È buona prassi procedere a visualizzare i dati solo dopo aver diviso il dataset in training e testing. Il nostro cervello è infatti un sofisticato sistema d’individuazione di pattern: così facendo eviteremo di creare pericolosi bias sui dati.
La parte pratica farà uso di un comune dataset canadese che fornisce indicazioni sull’immigrazione dal 1980 al 2013.
Trattandosi di un file xlsx, useremo un metodo di pandas.
Avviamo un jupyter notebook in locale, o su Google Colab, e prepariamoci all’esplorazione importando il dataset:
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# use the inline backend to generate the plots within the browser
%matplotlib inline
df = pd.read_excel('https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DV0101EN/labs/Data_Files/Canada.xlsx',
sheet_name='Canada by Citizenship',
skiprows=range(20),
skipfooter=2
)
df.head()Con l’ultima funzione di assicuriamo di aver correttamente importato il dataset!
Vediamo adesso il primo Data Visualization Tools in Ptyhon
Area Plot
Area Plot sono usati comunemente per rappresentare totali cumulativi usando numeri o percentuali nel tempo.
Si basano sui più semplici Line Plot, non riportati nell’articolo a facilmente consultabili dal notebook allegato in fondo.
Inoltre, ti consiglio di fare riferimento sempre al notebook per la parte pratica, poiché ho intenzionalmente saltato alcuni passaggi per ridurre all’osso il contenuto del post, concentrandoci unicamente sugli aspetti “teorici”.
La prima cosa che devi sapere è che gli Area Plot sono stacked per impostazione predefinita. Per produrre un’area plot tutte le features devono essere o positive o negative, con i valori NaN automaticamente portati a 0.
Per produrre un plot unstacked possiamo passare l’attributo stacked=false.
df_top5.index = df_top5.index.map(int) # let's change the index values of df_top5 to type integer for plotting
df_top5.plot(kind='area',
stacked=False,
alpha=0.25, #deffautl value to .5
figsize=(20, 10), # pass a tuple (x, y) size
)
plt.title('Immigration Trend of Top 5 Countries')
plt.ylabel('Number of Immigrants')
plt.xlabel('Years')
plt.show()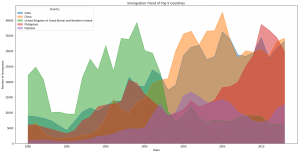
Histograms
Un istogramma è particolarmente utile nel rappresentare la densità frequenza di una distribuzione statistica per una variabile numerica.
L’asse x è banalmente diviso in segmenti (bins) e ciascun datapoint è associato a un bin; quindi viene calcolato il totale di datapoint per ciascun bin e si determina in questo modo l’altezza della colonna: è la frequenza.
L’ampiezza dei bin è determinata automaticamente ma spesso è necessario correggerne il valore per una migliore rappresentazione.
# view 1999 data
df[1999].plot(kind='hist', figsize=(8, 5))
plt.title('Histogram of Immigration from 195 Countries in 2013') # add a title to the histogram
plt.ylabel('Number of Countries') # add y-label
plt.xlabel('Number of Immigrants') # add x-label
plt.show()
Bar Charts
Un grafico a barre consente la rappresentazione di dati numerici e categoriali attraverso una serie di colonne la cui lunghezza esprime la magnitudine della feature.
df_iceland.plot(kind='bar', figsize=(10, 6))
plt.xlabel('Year') # add to x-label to the plot
plt.ylabel('Number of immigrants') # add y-label to the plot
plt.title('Icelandic immigrants to Canada from 1980 to 2013') # add title to the plot
plt.show()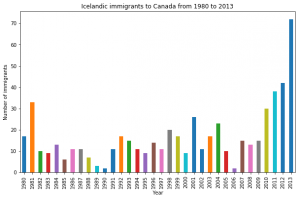
Qui, il link al file.
Buona sperimentazione!
Un caldo abbraccio, Andrea



